.
Besides, what is histogram SQL Server?
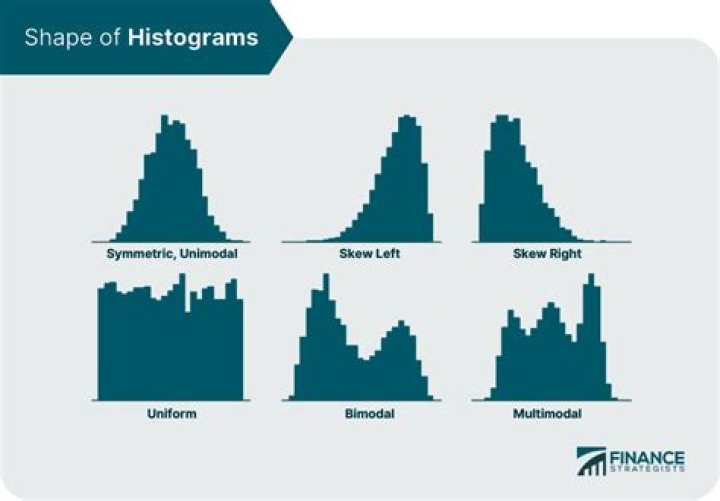
To create the histogram, SQL server split the data into different buckets (called steps) based on the value of first column of the index. Histogram is a statistical representation of your data.In other words it is the distribution of records based on the value of first column of the index.
Subsequently, question is, what is the use of histogram in Oracle? Histograms are a feature of the cost-based optimizer (CBO) that allows the Oracle engine to determine how data is distributed within a column. They are most useful for a column that is included in the WHERE clause of SQL and the data distribution is skewed.
Just so, what is histogram in database?
A histogram is a special type of column statistic that provides more detailed information about the data distribution in a table column. A histogram sorts values into "buckets," as you might sort coins into buckets. Based on the NDV and the distribution of the data, the database chooses the type of histogram to create.
What is distribution in SQL?
A distribution column is a single column (specified at table creation time) that SQL DW uses to assign each row to a distribution. For example, query performance improves when two distributed tables are joined on a column that is of the same data type and size.
Related Question AnswersWhat are SQL statistics?
Distribution statistics are used by SQL Server's Query Optimiser to determine a good execution plan for your SQL query. The statistics provide information about the distribution of column values across participating rows, helping the optimizer better estimate the number of rows, or cardinality, of the query results.What is bucket count in SQL Server?
In most cases the bucket count should be between 1 and 2 times the number of distinct values in the index key. If the index key contains a lot of duplicate values, on average there are more than 10 rows for each index key value, use a nonclustered index instead.What is bucket in histogram?
To construct a histogram, the first step is to "bin" (or "bucket") the range of values—that is, divide the entire range of values into a series of intervals—and then count how many values fall into each interval. The bins are usually specified as consecutive, non-overlapping intervals of a variable.What is data skew in Oracle?
(The term skew is defined in Oracle documentation to mean uneven data distribution; in traditional statistics, the term skew has a more precise meaning pertaining to the variation of normal distribution, such as positive or negative skew.)What is gather stats in Oracle?
You can use this package to gather, modify, view, export, import, and delete statistics. You can also use this package to identify or name statistics gathered. The DBMS_STATS package can gather statistics on indexes, tables, columns, and partitions, as well as statistics on all schema objects in a schema or database.What is Oracle bucket?
In the Oracle Cloud Infrastructure Object Storage service, a bucket is a container for storing objects in a compartment within an Object Storage namespace. The compartment has policies that indicate what actions you can perform on a bucket and all the objects in the bucket.What is Oracle cardinality?
It is a measure of the number of distinct elements in a column. In the context of execution plans, the cardinality shows the number of rows estimated to come out of each operation. The cardinality is computed from table and column statistics, if available. [1] If not, Oracle has to estimate the cardinality.What are the types of distributed database?
Types of distributed databases.- Homogeneous distributed databases system: Homogeneous distributed database system is a network of two or more databases (With same type of DBMS software) which can be stored on one or more machines.
- Heterogeneous distributed database system.